
Understanding the Machine Learning Project Life cycle
A blog covering all the important elements of an ML project lifecycle.

Write blogs about software and data.
Machine Learning Project Life cycle
Machine Learning (ML) projects follow a specific life cycle, similar to the DevOps cycle, that guides the development and deployment of ML models. The ML project life cycle consists of several stages that ensure a consistent and efficient way to take your ML projects into production.
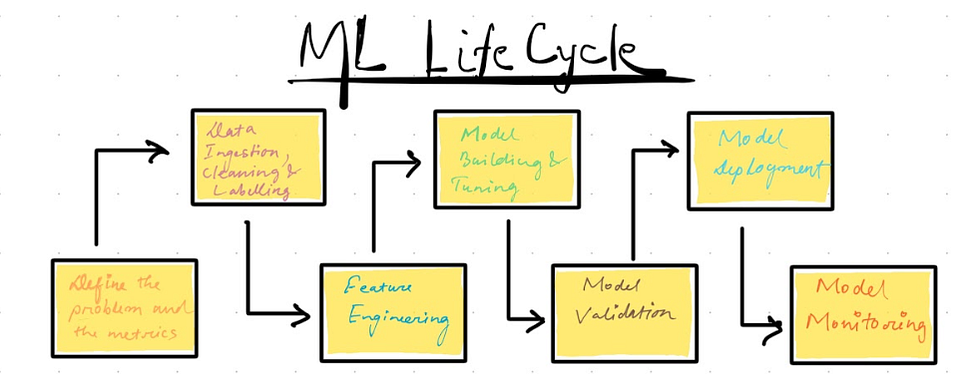
Let us go through each one of them in brief
Define the problem and metrics
The first stage of the ML project life cycle is to codify the problem and define success metrics.
In this stage, the team evaluates if the given business problem can be solved using ML and defines a success criterion to assess the prediction of the model.
The team consists of data scientists and the business subject-matter expert (SME) at a minimum.
A subject-matter expert (SME) is a person who has specialized knowledge or skills in a particular field or domain. In the context of machine learning projects, a SME is typically a person who has a deep understanding of the business problem that the project is trying to solve, and can provide valuable insights and guidance on how to best approach the problem using machine learning techniques.
Data Ingestion, Data cleaning and Data labelling
The second stage is to ingest, clean, and label data. The team assesses if the data required to train the model is available and builds components to ingest data from a variety of sources, clean the captured data, possibly label the data, and store it.
Data ingestion is the process of acquiring and importing data from various sources into a data storage system for further processing and analysis. In the context of a machine learning project, data ingestion is the first step in preparing the data for training and evaluating the models.
It involves collecting data from various sources such as files, databases, or external APIs, and then cleaning and pre-processing the data to ensure that it is in a format that can be used by the machine learning algorithms.
Data ingestion also includes data validation to ensure that the data is accurate and complete.
Data cleaning is the process of identifying and removing or modifying inaccuracies and inconsistencies in data sets to make them usable for analysis. It is an essential step in the data preparation process for machine learning projects as it helps to ensure that the data is accurate, consistent, and free of errors. Data cleaning can involve tasks such as removing duplicate records, fixing errors in data entry, removing outliers, and filling in missing values.
Data labelling is the process of assigning relevant labels or annotations to data. This is often done manually by human annotators, but can also be done through automated methods such as machine learning algorithms. Labels are typically used to classify or categorize the data into different classes or groups, making it easier to train machine learning models on the data.
It is an important step in the data pre-processing phase of a machine learning project, as it helps to ensure that the data is properly structured and ready for training.
Feature Engineering
The third stage is Feature Engineering (FE), which is about transforming the raw data into features that are more relevant to the given problem.
Feature engineering is the process of creating, transforming, and selecting features from raw data in order to improve the performance of a machine learning model.
It is a crucial step in the machine learning process, as it can have a significant impact on the final performance of the model.
Feature engineering typically involves the following steps:
Data Exploration: Understanding the structure, distribution, and relationships of the raw data.
Feature Selection: Identifying the most important features from the raw data that will be used to train the model.
Feature Creation: Creating new features from the raw data by combining, transforming, or aggregating existing features.
Feature Scaling: Normalizing or scaling the features so that they have similar ranges, which can help to improve the performance of some machine learning models.
Feature Encoding: Encoding categorical variables into numerical values so that they can be used by the machine learning algorithm.
This stage is critical as it helps to improve the performance of the model.
Modelling and Tuning
The fourth stage is Model building and tuning, where the team starts experimenting with different models and different hyperparameters.
The team tests the model against the given dataset and compares the results of each iteration.
The team then determines the best model for the given success metrics and stores the model in the model registry.
A model registry is a central repository that stores and manages the different versions of machine learning models. It is used to track the development, testing, and deployment of models, and provides a way to organize, collaborate on, and govern models.
Model Validation
The fifth stage is Model validation, where the team validates the model against a new set of data that is not available at the training time.
Model validation is the process of evaluating a model’s performance on a dataset that it has not seen during training. This is done to ensure that the model is able to generalize well to new, unseen data, and to identify any biases in the model.
During validation, the model’s predictions are compared to the true values of the data, and various metrics such as accuracy, precision, recall, and F1 score are used to evaluate the model’s performance.
Accuracy is a measure of how often a model correctly predicts the class of a given data point. It is the ratio of correctly predicted observations to the total observations.
Precision is a measure of how many of the positive predictions made by the model are actually correct. It is the ratio of true positives to the sum of true positives and false positives.
Recall is a measure of how many of the actual positive observations in the data are correctly predicted by the model. It is the ratio of true positives to the sum of true positives and false negatives.
F1 Score is a measure that combines precision and recall. It is the harmonic mean of precision and recall, where an F1 score reaches its best value at 1 (perfect precision and recall) and worst at 0.
This stage is critical as it determines if the model is generalized enough for the unseen data, or if the model only works well on the training data but not on the unseen data, avoiding overfitting.
Deployment
The sixth stage is Model deployment, where the team picks the model from the model registry, packages it, and deploys it to be consumed.
The deployed model can then be used to make predictions or classifications on new data. The process of model deployment can also include steps to monitor and maintain the model, such as monitoring its performance and updating it as necessary.
Traditional DevOps processes could be used here to make the model available as a service,
Some common methods include:
Model as a Service (MaaS): In this method, the model is deployed as a web service, and clients can access the model via an API endpoint. This allows for real-time predictions and easy integration with other systems.
Library deployment: In this method, the model is packaged as a library that other applications can use. This is useful when the model needs to be integrated with existing systems or when there are multiple applications that need to use the same model.
Containerization: This method involves packaging the model and its dependencies into a container (e.g. Docker) and deploying it on a container orchestration platform (e.g. Kubernetes). This allows for easy scaling and management of the model.
Cloud deployment: Many cloud providers offer machine learning platforms that allow for easy deployment of models. For example, Google Cloud ML Engine, AWS SageMaker, and Azure ML Studio provide a platform for training, deploying, and managing models.
On-Premises deployment: In this method, the model is deployed on-premises, typically on a server. This method is useful when data security and privacy concerns are high
Monitoring and Validation
The seventh and final stage is Monitoring and validation, where the model will be continually monitored for response times, the accuracy of predictions, and whether the input data is like the data on which the model is trained.
This stage is critical to detect and address any anomalies, such as outlier detection, and generate alerts to retrain the model with new datasets.
It ensures that the model continues to perform well over time and that any issues or changes in the data are detected and addressed.
In conclusion, the ML project life cycle is a crucial aspect of ML development and deployment, providing a consistent and efficient way to take your ML projects into production. Although the stages may look straightforward, in the real world, there may be several good reasons to go back to previous stages in certain cases.
Each stage plays a crucial role in the overall success of the project, and it’s important to pay attention to the details at each stage. It’s also important to keep in mind that in the real world, there may be instances where it’s necessary to go back to previous stages to address any issues that may arise.
By combining the ML life cycle with MLOps, organizations can achieve faster, more reliable, and more secure ML projects, making it easier for them to bring their ML models into production and maintain them over time.
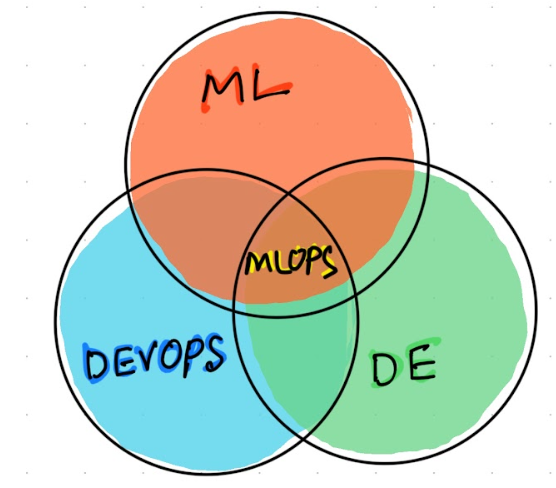
In this blog post, we’ve discussed the key aspects of each stage of the ML project life cycle and highlighted the importance of each stage in the overall success of the project.
Happy Coding💛



